$20 billion. That’s how much unplanned downtime is costing the chemical industry each year by some estimates. Yet producers continue to tackle issues reactively instead of spotting and fixing them early, before they become problems. The key to doing so lies in your data – and the Navigance Plant Monitor helps you turn it.
In this article we’ll cover:
- The costs of unplanned downtime in chemical plants
- The challenges of reactive maintenance and repairs
- Using technology for predictive monitoring and maintenance
- How that’s easier than you may think with the Navigance Plant Monitor
Downtime: it’s a costly business
For chemical producers, ensuring high levels of availability or ‘uptime’ in their plants is one of the key operational priorities. Many industry experts told us so in our comprehensive study of the chemicals landscape and its rate of digitalization.
It’s no wonder, when the cost of unplanned downtime can be so huge. According to some estimates, over 20 billion US dollars is lost each year in the chemical industry to unit or whole plant shutdowns. And these costs can manifest themselves in several ways, the impact of which can’t always be seen or quantified right away.

Perhaps most obviously, there’s the reduction in output that occurs when production slows or grinds to a halt altogether in the wake of a component or unit failure. If the incident is isolated to a particular unit production might still continue, albeit at a reduced rate. But if there’s disruption to the whole production line – a particular risk in continuous chemical processes – you could be faced with a full shutdown and significant loss of production.
There’s also the cost of time and materials spent on repairing issues or failures when they occur. Add to that the pressure to fix faults fast and you may find yourself paying a premium to get replacement parts on site quickly. Imagine if you could anticipate that you’re going to need it well in advance, rather than after it fails?
Another potential impact of downtime is on the quality of the product you’re making. Stopping and restarting your production process may cause periods where output quality isn’t of the required standard. This risks either increasing waste or upsetting the end customers the product is bound for.
This last point can’t be overstated, either: downtime can translate directly into dissatisfied customers. They expect a high-quality product to be delivered on time, every time. Any delays or defects hinder your ability to meet those demands and can create reputational damage not just with them, but potentially with their peers, who might be customers too.
To recap, there are four important cost drivers for unplanned downtime:
- Lost production
- Repair costs – including time spent
- Quality deviations
- Reduced customer satisfaction
Why aren’t plants spotting the signs?
Producers needn’t suffer such consequences any longer. The early warning signs of the process anomalies, deviations, failures, and other issues that lead to downtime are present in the data that’s already being routinely gathered across plant operations. It’s just that established control and monitoring systems can’t alert operators to them quickly enough.
In a traditional distributed control system (DCS), for instance, the standard approach is to set fixed limits for individual process variables. These typically include low or high thresholds for temperature, flow, pressure or vibrations, etc. Once one of these limits is reached, an alarm will be triggered for the attention of operators and engineers.
This approach is immediately limited because it’s inherently reactive – alerting and prompting a response only after the limit has been reached. The consequence is that, in many cases, problems may only be identified when it’s too late, and the limited time in which to react means downtime or quality deviations are inevitable.
What’s more, a problem with a piece of equipment that impacts several sensors or trends often results in operators being flooded with alarms. This issue, already well documented and investigated in the chemical sector, can lead to critical situations being missed.
Very commonly, busy plant teams don’t have the time or right tools to analyze massive volumes of data in order to trace issues to their source or spot new ones before they become problems or process limits are hit. Anticipating problems is as much down to chance as it is experience.
Rather, plant teams may, at most, find themselves retrospectively searching for patterns in the data to determine the root cause of an issue, and take steps to prevent it recurring. This predicament is often described as being “data rich but information poor,” as it’s hard to glean meaningful insights or predictions from the numbers
It’s time to shift the focus from simply getting systems back up and running quickly to ensuring they don’t go down in the first place. The tools and expertise needed to do so are now within much easier reach.
The right tech can work wonders
Technologies such as machine learning and other types of artificial intelligence offer the potential to introduce predictive monitoring and maintenance that’s driven by your data and suits the way you work.
An important difference is how such tools are put to work. Some tools that harness your process data are entirely self-service, so require a commitment of plant personnel’s time to analyze and interpret the findings they uncover. Examples of such tools include Seeq and TrendMinder. Other solutions go further, though, providing proactive alerts and insights as a service that teams can understand and act on immediately, or dive deeper into the data where needed.
At Navigance, we provide these as standard together with ongoing support and insights from our process and data science experts before, during and after deployment. We call this combination of technology and expertise the Navigance Plant Monitor.
It can be introduced into your plant environment quickly, without the need to change major workflows. And it frees up rather than ties up your plant team, so they can focus their energies where they’re needed most.
Intelligent plant monitoring
The Navigance Plant Monitor is cloud-based software as a service (SaaS) that takes secure and continuous uploads of your process data, and uses advanced analytics algorithms to monitor your operations around the clock.
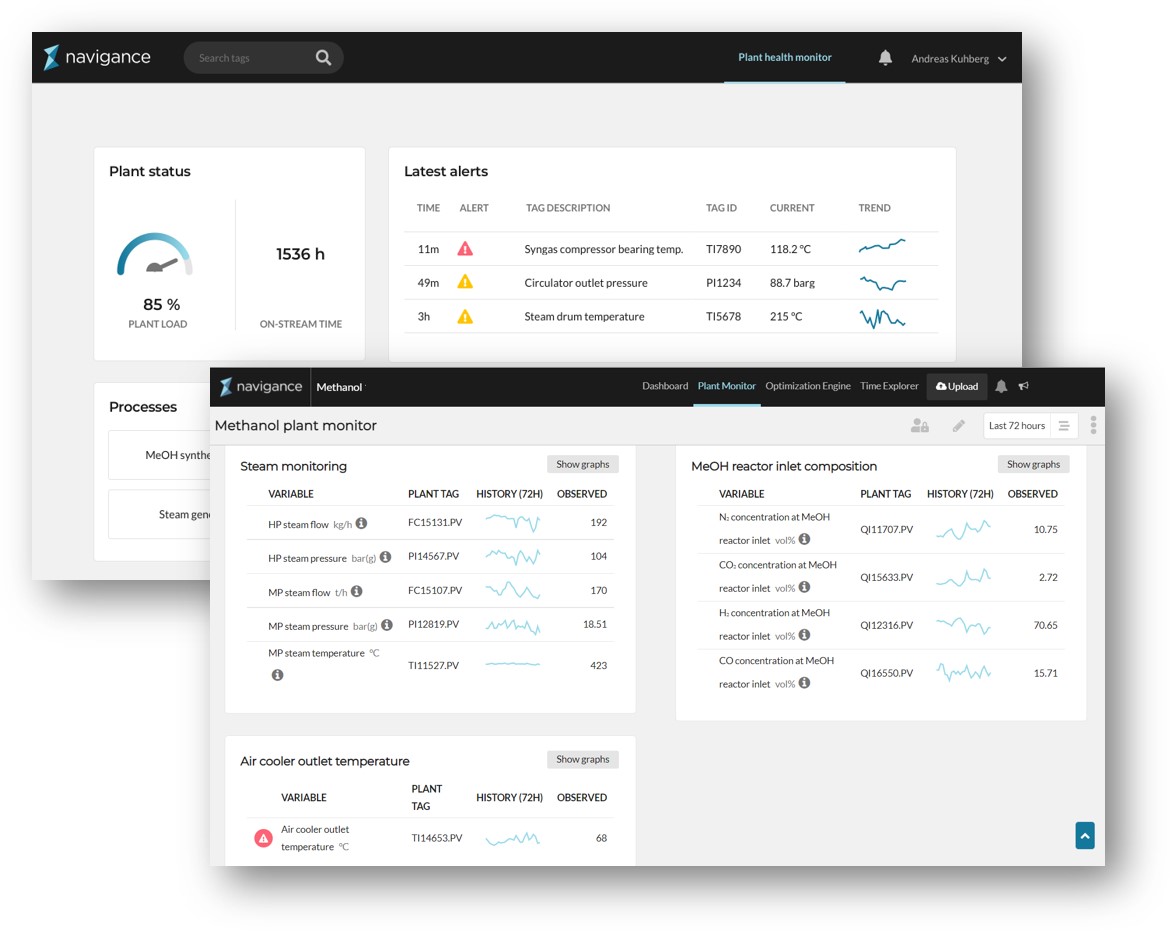
It can be flexibly deployed in any continuous chemical process, either covering the full process across unit operations and equipment or just specific parts of a plant.
The technology automatically scans for and detects anomalies, deviations and any other potential issues that might cause a larger issue if left unchecked. More specifically, it takes a three-fold approach to plant monitoring that consists of:
- Pattern recognition, which detects frequency variations or sudden changes in the distribution of patterns within your process,
- Predictive monitoring, which captures any long-term trends and changes in the data, and
- Sensor anomaly detection, which spots any deviations or faulty sensors
Proactive alerting and action
Suspicious readings and potential problems trigger proactive alerts, which are sent to the defined plant team members who need to know about and act on them. Unlike in alarm-heavy DCS systems, though, operators are sent a single, meaningful, pre-aggregated alert of all anomalies, including both short-term phenomena and long-term trends.
Receiving these single alerts before any process limit is hit or issues develop further enables them to quickly pinpoint the potential root cause. They can then troubleshoot and take appropriate, focused, effective action quickly, before issues ever become problems. This reduces and potentially avoids altogether the risk of unplanned downtime.
Alerts can be received in the operator’s preferred format:
- As notifications within a customized, intuitive web dashboard,
- By email or text message, or
- In daily summary emails
What’s more, secure role-based access to the Plant Monitor’s insights, including recent and longer-term trends, can be granted to whoever needs to collaborate on addressing them. This can include Navigance’s own team of experts, who are ready to provide advice to help keep your operation running smoothly.
In future blog posts we’ll look closer at some of the specifics of how the Navigance Plant Monitor works, such as its detection methods, use cases, and steps to implementation.
You can find out more now on the Navigance Plant Monitor page or talk to us about what it could mean for availability in your own operation.
Explore further:
Chemical process models – from first principle to hybrid models
In this article, we explore the role, common uses and limitations of the first principle approach to chemical process modeling. And we contrast this with the advantages and disadvantages of using empirical or statistical models.
We then look at how taking the first steps into new, intelligent 'hybrid' models can deliver the best of both approaches and more than the sum of their parts.
