

本文中,我们将探讨化工工艺建模的第一原理方法的作用、常见用途和局限性,并将其与使用经验模型或统计模型的优缺点进行对比。
然后,我们探讨迈出第一步进入新的智能“混合”模型如何做到两全其美,达到一加一大于二的效果。
继续往下读,您会发现基础已经打好,可以帮助您沿着这条路开始进行连续的、持续的和数据驱动的工艺优化。
模型及其重要性
模型对于化工行业和工程学而言,是一种重要的工具。它们实质上是(实际)系统中变量之间关系的数学表达,描述并帮助运营商理解工厂行为或工艺行为。
它们有不同的形状和大小。采用各种方法和技术构建。提供不同的功能和好处。当然也有自己的局限性。因此,为了构建和使用能够提供最大运营优势的模型,理解这些差异很重要。
那么化学过程工程中最常用的类型是什么? 在回答关键问题(例如,在何处以及如何进行优化)时,它们的优缺点是什么?
对比方法
区分不同模型类型的一个特征是,对发展所需的化工工艺中潜在的物理或化学现象的了解程度。
有许多对比标准:线性与非线性,离散与连续,静态与动态,显式与隐式,确定性与概率性。更具体地说,有第一原理模型和经验模型,两者迥然不同。
第一原理或“基于知识”的模型始于已建立的科学基础,已被普遍接受并已得到广泛验证。使用科学和工程(包括化学工程)中明确的、公认的相关性。一个著名的例子就是阿伦尼乌斯(Arrhenius)方程,描述了不同反应速率对温度的依赖性。
相比之下,经验模型纯粹基于任意的数学相关性,描述了来自任何观察过程或数据集的可用数据之间的关系。
原则上,这些方法的结果可以与流量、成分、温度、压力和其他变量的测量结果进行比较,从而描绘出工厂行为的真实画面。当然,收集这些测量数据又是另一个挑战。
让我们具体来了解每种模型类别。
第一原理模型:让知识发挥作用
第一原理模型建立在对基本的“从头开始”的物理化学现象的基本理解上,如传质、传热和质量流。通常,也基于化工工艺中特定单元操作的显式关系。通过工艺流程中的质量和热量平衡,可用于将不同的单元操作连接起来。
第一原理建模被广泛用于帮助设计新工厂。在许多情况下,可以建立一个将第一原理与诸如传热、孔隙率和蒸汽压等相关性相结合的流程模型,来描述整个工厂的规模。但这可能需要多年(甚至几十年)的工作,大量的资源和高额的投资。
这些模型通常也是改造工厂、消除瓶颈或支持和优化日常流程运作的起点。但是,常常需要观察到的“真实世界”数据,在参数未知或缺失的情况下“填补空白”。对知识的需求
第一原理模型依赖于大量信息,从工艺中涉及的化学物质和混合物的性质,到有关反应(如动力学)和热力学的数据。
还需要对潜在的相互关系有全面、真实的了解,这就需要来自不同学科的专业知识,包括设备制造商、工艺许可方和催化剂供应商,才能准确地描述一种化学操作。
一些信息可以在现成的化学工程文献中找到。其他更具体的数据则必须从具体实验中收集。这无疑是一个挑战。
在真实的业内场景中,观察到的行为可能会明显偏离我们期望看到的典型相关性(例如,化学混合物形成共沸物的情况)。原因是我们对某些现象的理解是有限的,比如非理想的混合物,或者多孔系统中的传热和传质。
因此,化学工程师的传统做法是依靠无因次数方法,如表格式传热关联或气液平衡(参见VDI Wärmeatlas, Dechema Datenbank)。解决方法并不仅限于此。
参数的问题
所有第一原理模型都依赖于足够的参数,这些参数适用于所描述的特定工艺或要解决的问题。得到它们说起来容易做起来难。
获取所需信息的一大挑战是,从基础效应看向同样影响化工工艺的次级效应时,通过(直接)测量的可获得性随着所涉参数的复杂性和数量的增加而降低。
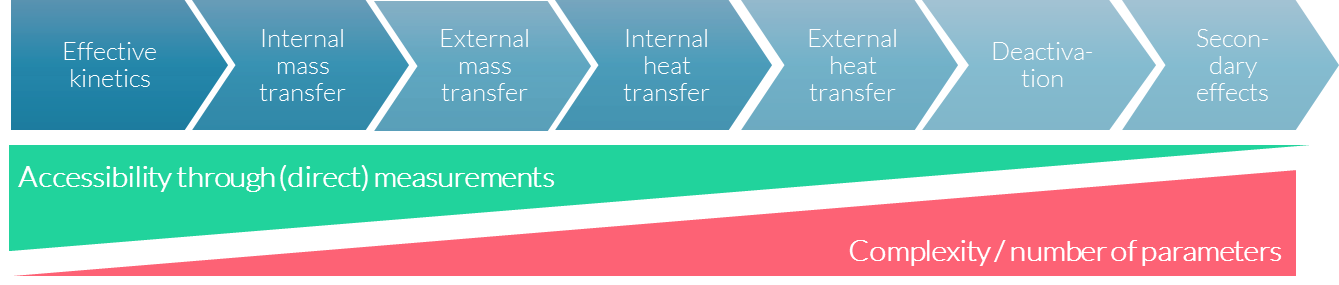
由于获取正确的测量参数变得越来越难,因此自下而上精确地建模真实世界的问题会变得越来越复杂。
尽管几十年来的研究试图弥合这些差距,但不确定性仍然存在,在现实世界工业系统中观察到的现象仍然无法得到充分描述。很容易得到成千上万的模型方程式,通常还伴有偏微分方程式,无法用分析法来解决。在许多情况下,即便用数字来解决也难度不小。所以“其他元素”开始发挥作用。
这些参数用于将模型输出与观测到的数据拟合,或用于工厂设计中的设计和安全边际。本质上,它们弥补了模型中的未知或不确定因素,无疑也弥补了第一原理方法整体上的不足。但是这种近似结果会在最终结果中留下显著的不精确性,意味着无法完全确定地捕捉所有的结果。寻找一种更容易的答案
我们应该知道,如果投入足够的时间、预算和精力,几乎任何事情都可以用这种方式建模,并交付质量合理可靠。但是,由于要依赖工程手册,因此第一原理方法的有效性总是有限的。
如果要帮助设计新工厂、改造旧工厂、减少瓶颈或提高工艺效率,那么基于知识的模型需要在多个方面发挥作用。必须有足够的空间进行推断。为优化提供光滑、连续和可区分的基础。而且,在工艺、设备和催化剂可能发生重大变化的环境中,它们必须容易适应,并被不断审查,以保持与时俱进。
为了优化一个化工工艺,是否真的需要所有传统的第一原理的工作?毕竟,一座现有工厂是由其所安装的设备或催化剂等特性来定义的。其行为可以用内部测量到的数据来描述。
因此,至少在现有数据的范围内,不需要设计新工厂通常需要的推断能力来对工艺进行建模或描述。从工艺中获取的数据作为一种资产,无疑提供了最大范围来了解需要优化哪些内容。
现在让我们看看另一个极端:经验模型。
第一原理模型:让知识发挥作用
纯统计模型用于描述观察到的数据和行为,使用任意函数在模型的输出和观察值之间找到一个良好的拟合。即使很少或没有物理或化学工程知识,也可以应用这类模型,但需要谨慎。
化工工艺的一个特征就是,变量和影响因素之间非常复杂的相互作用。有些,比如进料流量和反应器温度,可以直接或间接地控制。其他外部因素,比如环境湿度和温度,可以影响过程,但本身不受影响。
如果只看化工厂的数据,而不应用任何领域知识,很容易基于“伪相关性”得出错误的结论。这是指至少两个事件或变量显示出相同或相似的趋势,尽管它们之间没有联系(或“因果关系”)。这可能纯粹是巧合,也可能是第三种未知的因素导致的。
一个很好的例子是,将美国小姐的平均年龄与由蒸汽、热蒸汽和高温物体所导致的谋杀案数量相对比,时间跨度为10年。这听起来可能很荒谬,的确很荒谬,但这只是Tyler Vigen在他的伪相关性系列中收集的几组极端又滑稽的数据之一。
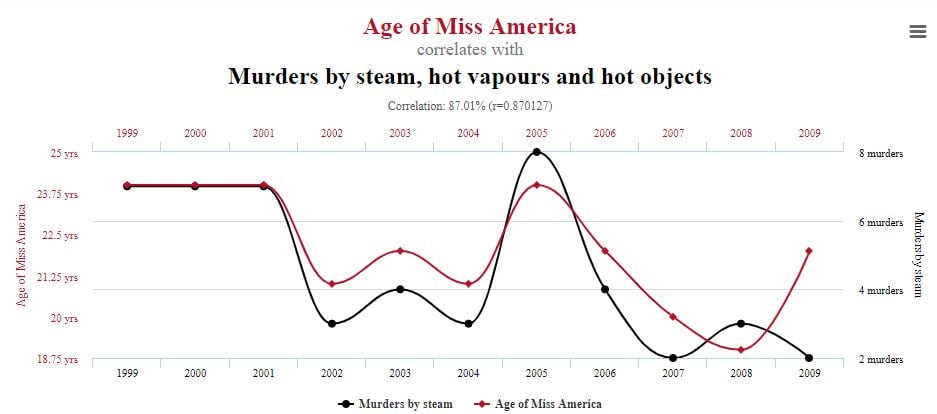
在得出结论之前请仔细查看数据。相关性可能纯粹只是巧合。
来源:Tyler Vigen,伪相关性(数据来源:维基百科;美国疾病控制与预防中心)。特此致谢。
统计的缺点
这样做是为了显示,单单数据集不一定能说明趋势之间的关系是否是由于似是而非的相关性,更不用说给出因果推断了。
更棘手的是,在化工工艺中,滞留时间也起着重要的作用。在输入(比如进料流)和输出(比如产品流)之间存在一定的时滞。如果入口的进料流发生改变,可能需要数小时后产品流才会出现相应的变化。这可能是由于工厂中的延误、化学反应平衡缓慢、温度等原因造成的。缺乏特定的领域知识和工艺知识,也会增加寻找趋势之间关联的难度。
仅仅依靠统计参数可能会产生很大的误导。可能看起来正确,其实无法准确地把握基本关系 - 统计学中的数据集Anscombe’s quartet及Datasaurus Dozen 都很好地分析了这一现象。此外,无法回避的事实是,正确的统计需要大量的数据。您了解得越少,就需要得越多。
因此,虽然统计模型各有用途,但它们不能反映长期的化学工程知识,可能会经常矛盾或误导,无法跟上化工工艺的实际操作情况。许多使用它们的化工生产商都报告了这类缺点。即使使用大量数据,也无法通过高级分析或机器学习技术来解决这些问题。
幸好还有另一种方法:
混合模型:两全其美
我们已经讨论过的第一原理方法和经验模型的一些缺点和局限性,可以通过使用混合模型来克服。
混合模型也有不同的形状和大小。它们的共同之处在于,在某种程度上仍然依赖第一原理领域知识,并在缺乏知识或知识不能充分描述现实的情况下,与统计方法相结合。
混合模型结合了两种方法的优点,同时也带来它们自身的优点。这并不是什么新概念。
利用数据驱动的神经网络和混合模型对化学反应系统进行动态建模已经是20年前的事了1。然而,成功地使用它们需要技巧。重要的是,要预先确定混合模型真正能够实现其设计目标——比如工艺优化。(当然,也要知道自身的局限性。)
当今的化工厂运营中,优化主要取决于操作人员和工程师的知识和经验。如果时间和预算允许,还可以对现有的任何数据进行基本和定期分析,作为补充。
是否有可能在不投入时间和资源的情况下进行连续和持续的优化?可以的。数字化和最新技术已经为化工生产商提供了在该领域取得巨大进步的机会。
我们让模型能做得更多
Navigance采用一种新方法,发现化工工艺中未开发的潜力。我们开发出下一代混合工艺模型,可以轻松地适应工厂的历史和实时数据,生成可靠的说明性建议,帮助您不断优化运营。
这些混合模型与第一原理模型相比如何?它们仍然使用已建立的第一原理技术、理化关系和工程原理作为基础。这确保了,比如说,质量平衡是封闭的;并且在化工工艺中的因果关系,如滞留时间,被正确地捕获。
作为一个起点,我们使用一种利用化学工程专业知识构建的特定工艺的基础模型。然后检查您的工厂、设置、您可用的传感器和测量值,以及任何运营上的限制,并确定相关的工艺数据,以衡量和优化性能。
正是这些工艺数据使我们的混合工艺模型得以实现。通过使用从数据中得出的任意函数,仔细地集成未知数,我们的模型可确保适用于观察到的所有数据。
我们非常小心地确保捕获和考虑工厂中的所有相关结果,然后应用高级机器学习技术,创建出AI增强的、数据驱动的混合工艺模型,与严格而僵化的第一原理模型相比,这种模型可以直观地学习并快速适应变化的条件。
利用智能算法考虑从连续物流中观察到的所有数据,可以产生宝贵的见解。这样,您就可以对可能影响工艺的许多因素作出快速反应——从不同负荷的场景到催化剂失活。
所有这些都意味着您可以对工艺控制变量的实时建议采取快速、自信的行动,以达到优化目标和最紧迫的关键绩效指标。
点击此处了解更多关于我们如何做到这一点。或者让我们谈谈如何为您做到这一点。
注释
[1]《运用神经网络和化学工程与技术混合模型的化学反应系统的动态建模》作者:Hans‐Jörg Zander、Roland Dittmeyer、Josef Wagenhuber (1999年7月8日) https://doi.org/10.1002/(SICI)1521-4125(199907)22:7%3C571::AID-CEAT571%3E3.0.CO;2-5
另见其他出版物如《Molga And Westerterp》(1997年),《Zander et al》(1999年)和《Molga And Cherbanski》(1999年)
查看更多: